Incident-Related Twitter Datasets
Authors: Axel Schulz, Christian Guckelsberger

These datasets comprise labeled tweets from 10 major cities in the English-speaking world.
The tweets were selected and labeled for the domain of incident detection.
Authors: Axel Schulz, Christian Guckelsberger
These datasets comprise labeled tweets from 10 major cities in the English-speaking world.
The tweets were selected and labeled for the domain of incident detection.
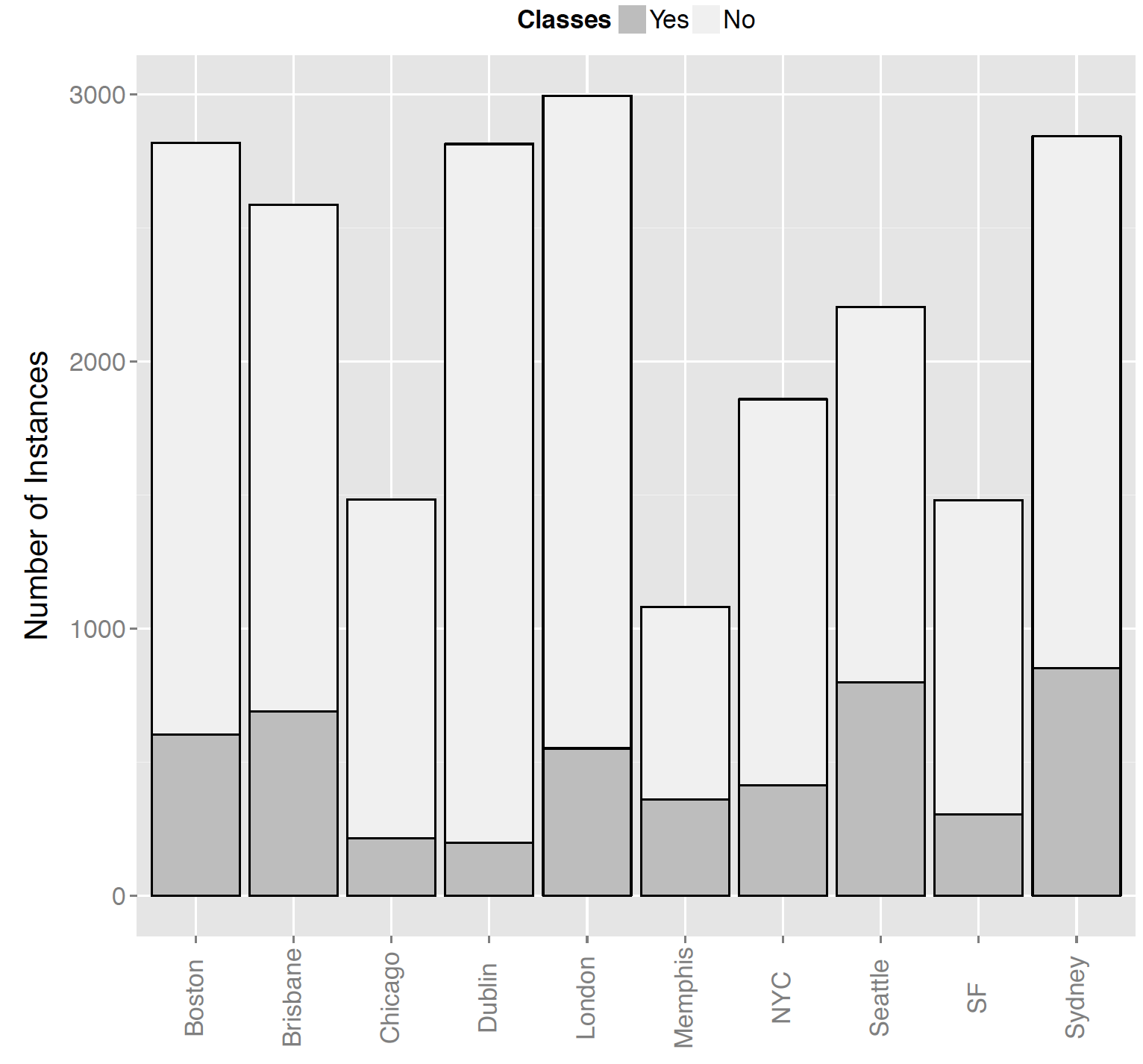
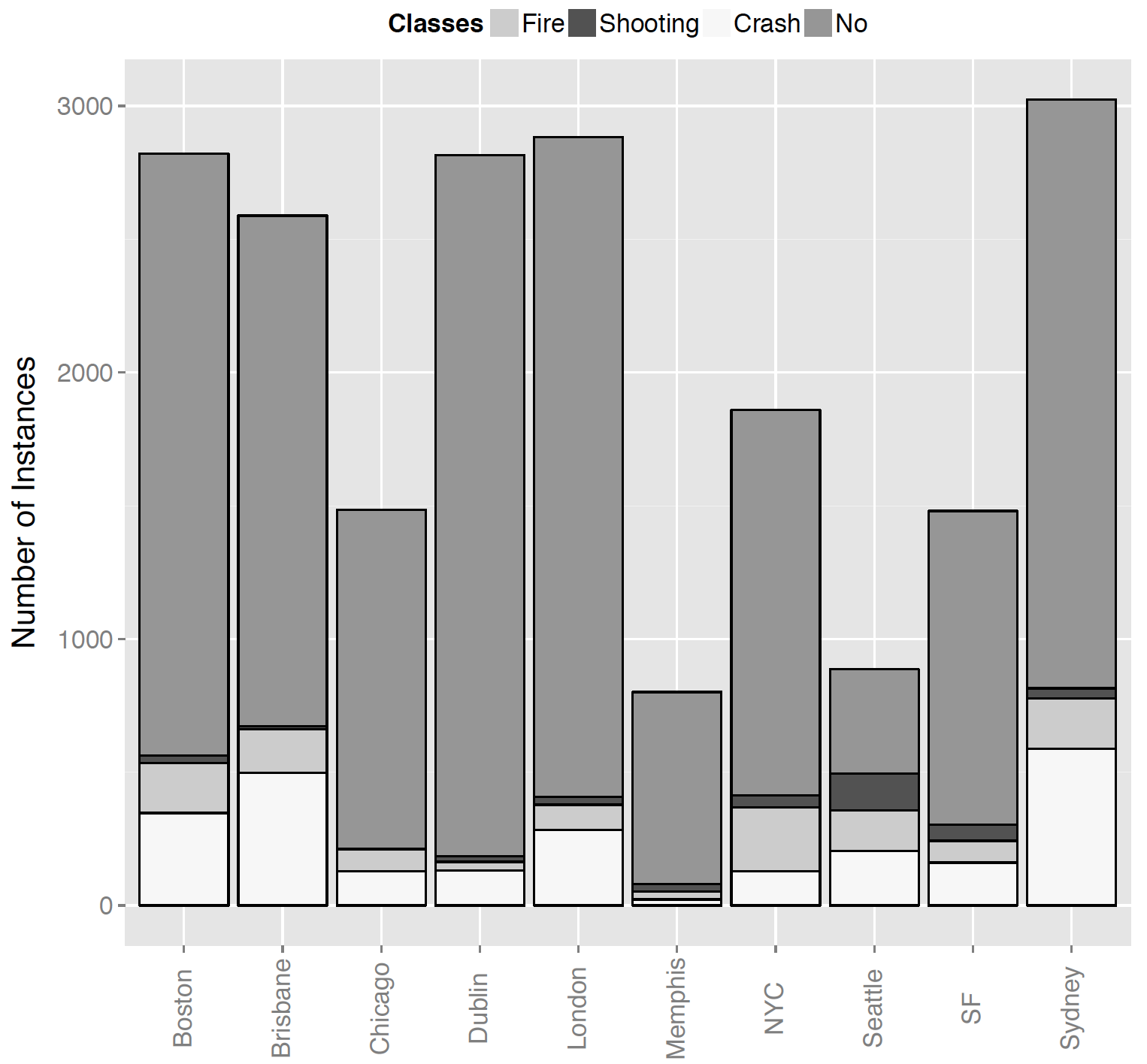
As ground truth data, we collected tweets in a 15km radius around the city centers of Boston (USA), Brisbane (AUS), Chicago (USA), Dublin (IRE), London (UK), Memphis (USA), New York City (USA), San Francisco (USA), Seattle (USA) and Sidney (AUS), using the Twitter Search API. We selected these cities as they have a huge regional distance, which allows us to evaluate our approaches with respect to geographical variations.
The Tweets were collected during different time periods:
As manual labeling is expensive and we needed high-quality labels for our evaluation, we had to select only a small subset of these tweets. In the selection process, we first identified and gathered incident-related keywords present in our tweets. This process is described in more detail in \cite{SchulzESWC13}. Following this, we filtered our datasets by means of these incident-related keywords. We then removed all redundant tweets and tweets with no textual content from the resulting sets. In the next step, the tweets were manually labeled by five annotators using the CrowdFlower platform.
The annotators distinguished the tweets into to two- and four classes, respectively:
We retrieved the manual labels and selected those for which all coders agreed to at least 75%. In the case of disagreement, the tweets were removed. This resulted in the twenty datasets on this website, split in ten for each classification problem.
Please note that the datasets are password-protected. We adopted the following procedure from ICWSM. To obtain the password, please download and sign our Dataset Usage Agreement. In it, you agree not to redistribute the datasets. Furthermore, ensure that you cite one of the papers listed in the end of this page when using the datasets for a publication.
Email the signed agreement, as a PDF file, to Christian Guckelsberger (c.[surname][at]gold.ac.uk). In the body of your email, please include your name, your email address, and the name of your organization. If everything is correct, we will send you the password within five business days.
Please cite the following papers when using these datasets for a publication:
For questions or feedback, please contact the authors of the respective paper, e.g. Christian Guckelsberger.